|
PLUTO
4.0
|
|
PLUTO
4.0
|
ArrayLib (AL) is a library that supports parallel finite difference/finite volume computations on block structured meshes. It is based on the Message Passing Interface (MPI) paradigm. The purpose of AL is to provide a simple, easy-to-use tool for the rapid development of finite difference methods in simple multidimensional quadrilateral domains.
The AL library had been developed by Andrea Malagoli, University of Chicago in 1999. It was made publicly available by the author for research purposes only.
In PLUTO only some of the AL routines are used. Many of them are used as originally written, other, conversely, have been modified before use. Moreover, additional routines have been written for particular purpouses, as to perform IO in vtk format and asyncronous parallel IO.
In what follow, a) the AL phylosophy and b) the use of the AL routines used in PLUTO are described.
AL is a tool to facilitate the development of stencil-based computations, typically finite-difference/finite-volume methods, on distributed memory parallel machines.
AL basically provides an abstraction for distributed array objects, and simple interfaces to the underlying MPI routines. The parallelization model adopted in AL is the usual one of distributed arrays augmented with guard cells (ghost points) to deal with boundary conditions. The size of the guard cells is determined by the stencil of the discretized differential operator.
AL supports both cell-centered and staggered meshes (and a combination of both), and it provides basic functionality to
Parallel IO routines based on MPI/IO are also provided.
AL was originally designed as a library, with support for C and FORTRAN interface. In PLUTO version 4.0, the AL is no longer a library. The AL routines used have been included in the source code, with support for C only.
The architecture of AL is inspired by similar previous developments, and in particular the BlockComm library of Gropp and Smith.
A distributed array is defined as an object and it is identified by an integer number, called descriptor. The user modifies the properties of the distributed array by calling appropriate functions that take the descriptor as one of their inputs. The variables internal to the object are hidden from the user, and are accessible only via such functions. A strict object-oriented architecture is not implemented, so, for example, the buffer that contains the data for the distributed array is not incorporated into the object, and it is the user's responsibility to allocate it properly. The library provides the user with basic functionality decompose, and manipulate block-structured arrays distributed across several processors. This way, the user needs only to have a limited knowledge of the MPI paradigm.
The basic object in AL is a regular block-structured array that may be distributed across multiple processors. As it is usual, the array is augmented with guard cells or ghost points in order to implement boundary conditions on a given computational stencil. In this section, the basic ideas of stencil-based computations on regular meshes are reviewed, and the preliminary concepts and conventions that used in AL routine are introduced.
A regular rectangular domain that can be mapped onto a cartesian grid is often defined as a block-structured mesh. The domain is defined by and interior  , and by a boundary
, and by a boundary  . For the sake of simplicity, let's assume that the domain is discretized using a uniform spacing
. For the sake of simplicity, let's assume that the domain is discretized using a uniform spacing  in all spatial directions. For example, let's consider the 2D domain:
in all spatial directions. For example, let's consider the 2D domain: ![$ (x,y) \in [0, L_x] \otimes [0,L_y]\in R^2 $](form_7.png) , and let's assume that it is discretized in
, and let's assume that it is discretized in  by
by  cells with edge size , so that
cells with edge size , so that  and
and 
 by
by  with
with  and
and  .
.As shown in figure 1, the physical boundary of the array, the cartesian domain ![$ [0, L_x] \otimes [0,L_y]$](form_15.png) , is marked by the heavier border. The figure also shows the additional guard cells that are added outside of the physical domain in order to complete the computational stencil at the boundary (see next section).
, is marked by the heavier border. The figure also shows the additional guard cells that are added outside of the physical domain in order to complete the computational stencil at the boundary (see next section).
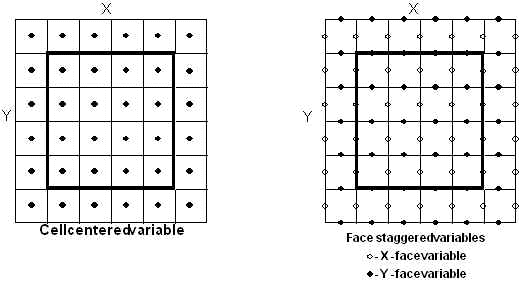
We can distinguish between several types of variables that can be defined on this mesh:
 with respect to the center of the cell (thus a variable staggered in X and Y would be defined at the cell corners, while a variable staggered in X only would be defined at the X-edges of the cell. See figure 2).
with respect to the center of the cell (thus a variable staggered in X and Y would be defined at the cell corners, while a variable staggered in X only would be defined at the X-edges of the cell. See figure 2).Therefore, if the physical domain is decomposed into by cells, a cell-centered variable will have size  , while a staggered variable defined along the X-edges of the cell will have size
, while a staggered variable defined along the X-edges of the cell will have size  .
.
Figure 2 illustrates the location of the collocation points for both a cell-centered variable (on the left) and for staggered variables (on the right).
The discretized operators used in finite difference and finite volume computations can be characterized by a computational stencil, which describes the number and distribution of cells required for the update of a given cell.
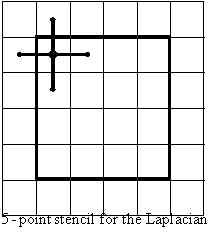
For example, consider the usual 5-point discrete Laplacian operator, which is a 2nd order approximation to the Laplacian operator on a mesh:
![\[ \Large{ \nabla \phi = \frac{1}{h^2} \big( \phi_{i+1,j} + \phi_{i-1,j} + \phi_{i,j+1} + \phi_{i,j-1} - \phi_{i,j}\big) + O(h^2) \qquad i=1,N_x,\quad j=1,N_y\Large} \]](form_19.png)
This operator can be described as a 5-point stencil operator on a mesh augmented with one layer of ghost points around each dimension of the mesh. During a calculation, the ghost points are filled with values appropriate in order to satisfy the given boundary conditions (see figure 3).
The most common way to parallelize a stencil based computation on a block structured mesh as the one represented in figure 1 is to decompose the global array in sub-arrays that can be assigned independently to each processors. In turn, the sub-arrays on each processors are augmented with their own layer of ghost points in order to enable the update of the internal points. Figure 4 shows an example of the decomposition of the array onto 4 processors:
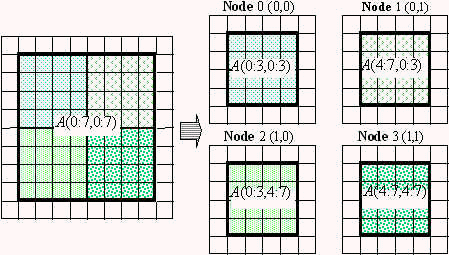
In this example, the original array is decomposed in 4 sub-arrays of equal size, and each sub-array is augmented with its own layer of ghost points on each processors (or nodes, as we use the terms interchangeably). If the original 8 x 8 array is A(0:7, 0:7), where we use the C convention to start indexes at 0, then each node would receive a 4 x 4 sub-array A(0:3, 0:3). On each node, the sub-arrays can be addressed using two types of indexes:
Typically, the local indexes are used in local do-loops on each processor, while the global indexes are used to compute the global coordinates of a grid cell.
Given such domain decomposition, a code on each node will function almost exactely like a standard single-processor code. A typical update loop will look like:
For n=0, n_iterations do
Update_boundaries()
Apply_operator()
Perform_IO()
...
End for
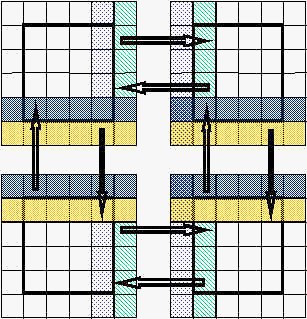
The parallelism enters mainly inside the Update_boundaries() routine. In fact, the boundary ghost points on each processor are of two types:
Physical boundary ghost points are updated in the usual way by assigning values that fulfill the chosen boundary conditions.
Inter-processors boundaries ghost points are filled by exchanging data among neighbor processors, as is shown in Fig. 5 below.
The function AL_Is_boundary(isz, is_gbeg, is_gend) [AL_Is_boundary()] returns two integer arrays, is_gbeg, is_gend, that are set to AL_TRUE (AL_FALSE) if the given layer of ghost cells for a given dimension is (is not) overlapping with the physical boundaries.
The data exchange is accomplished by sending messages among the processors using the MPI message passing standard. The actual calls to the message passing routines is hidden into the user-callable function AL_Exchange().
This function would be called typically at the beginning of the Update_boundaries() routine as shown in this pseudo-code:
Update_boundaries( my_data_type *array)
ierr = AL_Exchange(array, isz)
foreach (side_of_the_array)
if( this_side overlaps with the global boundaries) then
Fill_physical_boundaries()
end if
end for
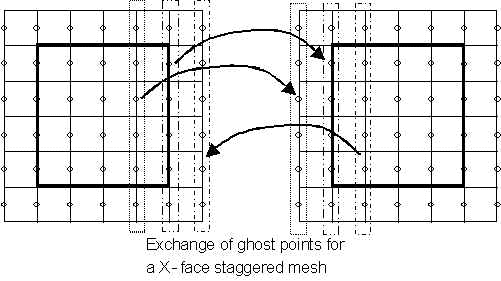
NOTE FOR STAGGERED MESHES : on staggered meshes, the internal points of the array that lie on the grid boundary between processors exist (and are updated) on both processors (see figure below). In this case, the convention is that the left processor physically owns these nodes, and that therefore the values of the updated points from the left processors over-write those computed on the right processor during the data exchange (see figure below).
The AL routines used in PLUTO have C interface.
The AL subroutine follow a standard naming convention. All subroutines and functions begin with the prefix AL_ and the first letter of the rest of the name is uppercase, while the rest is lowercase. For example AL_Get_ghosts(...). Most AL subroutines return an integer error code in C.
AL uses MPI data types. For convenience, the MPI data types are also translated to AL internal types by replacing the MPI prefix with the AL prefix. For example, AL_FLOAT is equivalent to MPI_FLOAT. Similarly, codes for MPI communicators and operations, are also available as AL codes (e.g. AL_COMM_WORLD is the same as MPI_COMM_WORLD, and AL_SUM is the same as MPI_SUM).
Typically, AL is started with a call to AL_Init(). This also calls MPI_Init(), and it starts the MPI message passing layer.
After this call, the user can begin to declare distributed arrays, and use them for computations. Each distributed array has an integer descriptor isz that points to an internal structure that contains all the information required to handle the distributed array. The descriptor is first allocated and initialized calling the function AL_Sz_init():
MPI_Comm Communicator; int isz;
ierr = AL_Sz_init( Communicator, &isz);
Here, Communicator is the MPI communicator which the distributed array is associated with. A MPI communicator is the group of processors among which the array is distributed.
AL is built using concepts inspired by the BlockComm library of W. Gropp and B. Smith, although substantial changes and re-design have been applied.
AL defines a single object, a block-structured distributed array (DA). A DA object defines a distributed array, which is augmented with several layers of ghost points. The ghost points are used to complete the definition of a computational stencil associated with a finite-difference or finite-volume operator. A DA object is identified by an integer descriptor isz which is a pointer to an internal AL structure with the information necessary to define and utilize the DA. The user interacts with the internal structure by manipulating the descriptor isz and by calling the appropriate functions (methods). This way, the user only needs to pass the isz descriptor to the applications subroutines, and all the information about, e.g., the parallel decomposition, can be obtained by calling the AL_Get_xxxxx routines.
NOTE: contrary to most object-oriented approaches, we do not associate the array buffer directly to the DA object. The main reason for doing this is to retain the ability to re-use the same DA descriptor to handle multiple variables, this saving the redundant duplication of overheads.
In order to allocate a isz descriptor, we call the function:
MPI_Comm Communicator; int isz;
ierr = AL_Sz_init( Communicator, &isz);
Here, Communicator is the MPI communicator which the distributed array is associated with. A MPI communicator is the group of processors among which the array is distributed (typically, Communicator = MPI_WORLD_COMM ) .
Subsequently, the user proceeds to define the properties of the distributed array, by setting various parameters via the isz descriptor. These calls typically are:
| ierr = AL_Set_type( AL_FLOAT, n_elements, isz); | Sets the type type and the number of elements of type type of a distributed array’s elements. The types are essentially identical to MPI datatypes. User defined types (e.g. MPI structures) are also possible. |
| ierr = AL_Set_dimensions( ndims, isz); | Sets the number of dimensions of the distributed array (e.g., ndims=3) |
| ierr = AL_Set_global_dim( gdim, isz); | Sets the global size of the distributed array (e.g., gdim[0]=nx; gdim[1]=ny; gdim[2]=nx) |
| ierr = AL_Set_ghosts( ghosts, isz); | Sets the size of the ghost points of the distributed array (e.g., ghosts[0]=nx; ghosts[1]=ny; ghosts[2]=nx) |
| ierr = AL_Set_staggered_dim( stagdims, isz); | Sets the staggered dimensions of the distributed array (e.g., stagdims[0]=AL_TRUE; stagdims[1]=AL_FALSE; stagdims[2]=AL_FALSE) |
| ierr = AL_Set_periodic_dim( periods, isz); | Sets the periodic dimensions of the distributed array. This is used by the MPI send and receive routines. (e.g., periods[0]=AL_TRUE; periods[1]=AL_FALSE; periods[2]=AL_FALSE) |
| ierr = AL_Set_parallel_dim( pardims, isz); | Sets the parallel dimensions of the distributed array. This is used to perform the array decomposition. (e.g., pardims[0]=AL_TRUE; pardims[1]=AL_TRUE; pardims[2]=AL_TRUE) |
Finally, after all the above properties have been defined, the call to the function AL_Decompose() computes and finalizes the decomposition of the distributed array.
At this point, all the necessary information can be retreived from the isz descriptor using the AL_Get_xxxxxx routines. For example:
ierr = AL_Get_local_dim( isz, ldims);
returns the local dimensions (i.e., the dimensions on the local processor) of the distributed array.
NOTE for PLUTO : In PLUTO, array descriptors for both cell-centered and staggered variables are defined.
For a cell-centered variable, the AL routines used are:
For a staggered variable, the AL routines used are:
The main difference is that in the staggered case, the AL_Set_staggered_dim() is called.
Once the isz descriptor is completely defined, after the call to AL_Decompose(), it can be used for two main purposes.
a = (arraytype *) AL_Allocate_array(isz);
or by doing manually:
ierr = AL_Get_type_size(isz, &type_size);
ierr = AL_Get_buffer(isz, &buffer_size);
a = (arraytype *)calloc(byffer_size, type_size);
These I/O procedures made using AL_Write_array() allow only one distributed array type to be written per file. As long as the file is open, consecutive calls to AL_Write_array() append new data to the end of the file.
 1.8.2
1.8.2

